
 AI na ścieżce zakupowej. Co mówi 11. edycja Raportu Omni-commerce?
AI na ścieżce zakupowej. Co mówi 11. edycja Raportu Omni-commerce?

Jakiś czas temu Agnieszka Zawadzka, Head of Research and Analysis w Whites, poprowadziła webinar na temat wykorzystania machine learningu w marketingu internetowym. Webinar w formie wideo cały czas jest dostępny pod linkiem. Temat spotkał się z dużym zainteresowaniem, postanowiliśmy więc przygotować artykuł, dla tych którzy wolą wersję pisaną. Zapraszamy do lektury.
Machine learning, deep learning, big data, sieci neuronowe, sztuczna inteligencja… buzzwordy, które atakują nas dziś zewsząd. Wiemy, że to już się dzieje – techniki uczenia maszynowego budują sukces firm takich jak Netflix, Google, Spotify. Dodatkowo popkultura, a zwłaszcza literatura i filmografia science fiction, ukształtowała w nas przeświadczenie o niemal nadnaturalnych mocach tkwiących w „sztucznych mózgach” – sieciach neuronowych. Do machine learningu podchodzimy więc zwykle z mieszanką grozy i zachwytu – jak do magii – niezrozumiałej, trudno dostępnej, bardzo kosztownej i nieco przerażającej. Tymczasem to tylko – i aż – matematyka.
W sumie niewiele więcej niż – znane nam z zadań maturalnych – badanie zmienności funkcji. Z tym że bardzo, bardzo wielu funkcji w oparciu o bardzo, bardzo wiele współczynników, które próbujemy dopasować. Problem tkwi nie w jakiejś alchemicznej formule czy w szczególnym matematycznym zaawansowaniu modeli, ale przede wszystkim właśnie w rozmiarze danych, niezbędnych, by znaleźć taki zestaw funkcji, które najlepiej opiszą obserwowane zjawisko. Specjalista uczenia maszynowego wybiera model – określa, jakiego rodzaju zestaw funkcji będzie brany pod uwagę. Może to być nawet najzwyklejsza funkcja liniowa! Mogą to być też wielomiany, funkcje wykładnicze, trygonometryczne – wzory znane od stuleci. W modelach opartych na sieciach neuronowych też nie ma magii – jest po prostu złożenie kilku funkcji po kolei.
Naprawdę, moglibyśmy policzyć to na kartce… Ba, mógłby to policzyć matematyk sprzed stu, a nawet dwustu lat. Dlaczego w takim razie ML święci triumfy od tak niedawna? Szukanie współczynników modelu to faktycznie zestaw prostych obliczeń – jednak trzeba ich wykonać naprawdę bardzo wiele. Do niedawna dysponowaliśmy zbyt słabym sprzętem, a dokładniej: komputery o odpowiedniej mocy obliczeniowej i przestrzeni dyskowej były na tyle drogie, że ich wykorzystanie biznesowe było po prostu nieopłacalne.
Jak więc działa machine learning?
Uczenie maszynowe to szukanie regularności w zebranych danych. Najprostszym przykładem jest uczenie nadzorowane (supervised learning), czyli na podstawie znanych wyników. Mamy zestaw cech charakteryzujących opisywany proces i wiemy, jaki przy tych cechach był faktyczny wynik. Powiedzmy, że chcemy rozpoznać gatunek zwierzęcia na podstawie różnych danych fizycznych: kolorze, liczbie kończyn, długości ciała, obecności skrzydeł itp. Wykonujemy więc na różnych zwierzętach pomiary i zapisujemy wartości poszczególnych cech, a obok, jako wynik – nazwę zwierzęcia (czy raczej nadany mu numer). Wykonujemy takich pomiarów jak najwięcej, żeby wyeliminować błędy w wykrywaniu wzorców.

W najprostszej interpretacji matematycznej spójrzmy na model liniowy: ax + b = y, wobec wielu parametrów nasz x będzie faktycznie wektorem cech: x = [x1, x2, …, xn] gdzie x1 to kolor (wyrażony numerycznie), x2 to długość ciała, x3 to liczba nóg itd., y natomiast to numer nadany zwierzęciu. Równanie będzie więc wyglądać następująco: a1 * x1 + a2 * x2 + .... + an * xn = y
Podstawiając kolejne wartości x i odpowiadające im wyniki y, staramy się dopasować współczynniki tak, żeby jak najczęściej trafiać w y. Ponieważ mamy do czynienia z uczeniem nadzorowanym – czyli na podstawie znanych wyników – możemy sprawdzić, w jakim stopniu nasze równania odbiegają od faktycznej klasyfikacji zwierzęcia. Starając się zmniejszać rozbieżność między przewidywaniem modelu a rzeczywistością, szukamy minimum dla błędu, czyli wykonujemy działanie dobrze znane z matematyki w liceum. Zasada jest, jak widzimy, prosta. Jednak dla osiągnięcia dobrego przewidywania trzeba wykonać jak najwięcej obliczeń na bardzo wielu pomiarach.
Poszczególne osobniki danego gatunku mogą znacząco różnić się wartością jednej z cech. Przykładowo, patrząc na 7-kilogramowego maine coona i 2-kilogramowego chihuahua, widać, że nie możemy na podstawie samej wagi udzielić odpowiedzi: co jest psem, a co kotem. Jednak cały zestaw czynników wykazuje pewien wzorzec, do którego poprzez kolejne podstawienia danych doświadczalnych program machine learningowy się coraz bardziej zbliża.
I właśnie istnienie takich wzorców prowadzi nas do kolejnej szeroko stosowanej dziedziny ML: do uczenia nienadzorowanego (unsupervised learning). Załóżmy, że wszystkich pomiarów cech zwierząt dokonujemy za pomocą automatycznych czujników, nie angażując przy tym człowieka, który przypisze mierzony egzemplarz do konkretnego gatunku. Wiemy, że w badanej grupie zwierząt mieliśmy 7 różnych gatunków. Możemy powiedzieć, że pies będzie „jakoś” podobny do innych psów, bardziej niż do koni czy kaczek. Możemy więc, nie podając konkretnych wyników dla poszczególnych egzemplarzy, dzielić je na grupy według podobieństwa. Tutaj kluczowa jest jednak wiedza o tym, z iloma grupami mamy do czynienia. To jest założenie, które trzeba wprowadzić do modelu na wstępie i jego błędne przyjęcie doprowadzi do niewłaściwego podziału. Na przykład, gdy wprowadzimy zbyt małą liczbę grup, model, próbując dzielić naszą menażerię, połączy gady z płazami lub koty z ptakami.
NLP – jak komputer rozumie język naturalny?
Programy nie są w stanie bezpośrednio zrozumieć słów – działają na wartościach numerycznych. Interpretacją języka zajmuje się od kilkudziesięciu już lat cała gałąź uczenia maszynowego – Natural Language Processing, czyli NLP. Na pierwszy rzut oka zagadnienie może wydawać się proste – każde słowo ze słownika otrzyma numer porządkowy i możemy prowadzić analizę tekstu. Jednak co z homonimami i polisemami? Na przykład zamek jako blokada w drzwiach i zamek jako budowla obronna? Lub wyraz „mam”, który może być czasownikiem o dwóch różnych znaczeniach („mam dwa ołówki”, „nie mam mnie próżnymi obietnicami”) lub rzeczownikiem („najlepsze życzenia dla naszych mam”). Intuicyjnie oczywiste jest też, że pewne słowa są bardziej, a inne mniej znaczące dla zrozumienia tekstu. Wiemy ponadto, że zamiana słowa na jego synonim nie zmienia znaczenia zdania – i tego też trzeba nauczyć model rozpoznający język naturalny. Znów do nauki potrzebne będzie dużo danych, do których dopasowywać się będą funkcje określone w modelu.
Jako pierwsze w analizie języka powstały modele działające na poszczególnych słowach – od wprowadzonego już niemal pięćdziesiąt lat temu TF/IDF poczynając (1972, Karen Spärck Jones). Ten model realizował pierwsze z założeń – czyli różnicował ważność słowa w danym dokumencie według jego popularności ogólnej (jeśli słowo często występuje w całym korpusie językowym, jest mniej istotne, daje mniej informacji charakterystycznej dla pojedynczego tekstu). Wagi nadawane przez TF/IDF nie uwzględniały homonimów, synonimów, kolejności wyrazów. Czyli tekst „Nie chcę tańczyć. Chcę czytać” był równoważny tekstowi „Nie chcę czytać. Chcę tańczyć”, co, jak łatwo zgadnąć, przysparza sporych problemów w faktycznym zrozumieniu, czego właściwie ten człowiek chce. Co gorsza, zdania: „zrób mi kawkę” i „zaparz dla mnie kawę” w ogóle nie leżały blisko siebie, co już może prowadzić do domowego dramatu! Język ma strukturę sekwencyjną i tak należy podejść do reprezentujących go modeli matematycznych. Tak też rozumowali twórcy word2vec – modelu, który przypisywał słowom liczby zależnie od kontekstu, w jakim dany wyraz najczęściej występował. W zbiorze uczącym, w którym mamy do dyspozycji ogromną pulę tekstów (to np. Narodowy Korpus Języka Polskiego, zasoby Wikipedii, common crawl) można sprawdzić, w jakim towarzystwie występują zwykle poszczególne wyrazy, i na tej podstawie przypisywać im wartości liczbowe, tak, by pies znalazł się blisko pieska a daleko od czołgu (chyba że uczymy model na „Czterech pancernych”). Ponieważ każde słowo niesie ze sobą wiele informacji, nie wystarczy przedstawienie go za pomocą pojedynczej liczby. Dlatego w komputerowym „słowniku”, jakim jest nauczony word2vec, każdy wyraz reprezentowany jest przez 300 liczb – czyli, w matematycznym ujęciu, stanowi 300-wymiarowy wektor. W ten sposób można oddać zależności między słowami i rozwiązać problem synonimów.
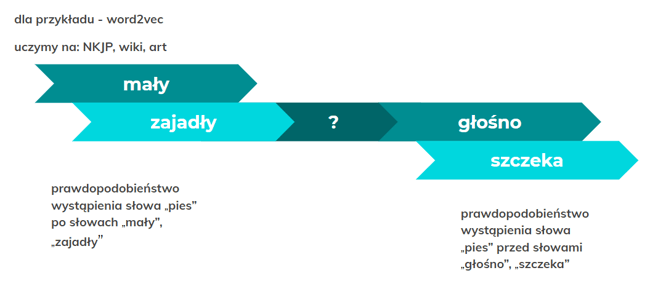
Sprawdzamy, jakie jest prawdopodobieństwo wystąpienia słowa „pies” po słowach „mały”, „zajadły” oraz równocześnie, jakie jest prawdopodobieństwo wystąpienia słowa „pies” przed słowami „głośno”, „szczeka”. Na podstawie kolejnych zdań pobranych z korpusu modyfikujemy 300 współrzędnych określających dane słowo. Słowa, które są bliskie znaczeniowo, będą miały podobne wektory. Tego typu modele dają nam podstawową możliwość zrozumienia przez algorytm słowa pisanego. Dzięki temu możemy nauczyć model rozpoznawać, np. że jeśli wprowadzimy zestaw wyrazów: „ospa”, „odporność”, „zastrzyk”, najbardziej zbliżone do tego zestawu będzie słowo „szczepienie”. Program jest w stanie wyłapać zależności między słowami.
Nadal jednak poruszamy się w obrębie pojedynczych słów. W zależności od tego, na jakim korpusie językowym uczyliśmy nasz model, słowo „kawka” będzie blisko kawy lub kruka. Nikt z nas nie chce dostać rano od domowego ekspresu poparzonego kruka. Żeby dobrze służyć ludziom, model powinien rozpoznawać cały zwrot „zaparz kawkę”, czego nie osiągniemy, przypisując na sztywno wartości poszczególnym słowom.
BERT
To bardziej zaawansowany model, który potrafi wyciągnąć wnioski z całych zdań. Rozpoznaje konteksty i jest w stanie ocenić, czy słowo „to” dotyczy zwierzęcia, czy np. ulicy. Uczy się tego, co jako ludzie robimy intuicyjnie: przypisuje poszczególnym słowom określoną wagę (atencję) w zależności od ich doraźnego kontekstu. To jest przełomowe odkrycie. Dzięki temu modelowi możemy używać uczenia maszynowego w działaniach contentowych oraz związanych z marketingiem.
Do jakich działań marketingowych można wykorzystywać Machine Learning?
Internet jest idealnym środowiskiem do stosowania uczenia maszynowego. A zwłaszcza marketing internetowy. Dysponujemy ogromną liczbą danych, które zbierają się automatycznie, większość systemów oferuje API, oprócz tego niskim kosztem możemy prowadzić testy – dzielić grupy docelowe, zmieniać najdrobniejsze szczegóły i sprawdzać reakcje – to idealne pole dla algorytmów. W internecie algorytmy mają na czym się uczyć i doskonalić swoje działanie. W reklamie i sprzedaży offline zgromadzenie takich danych byłoby szalenie kosztowne, a niekiedy wręcz niemożliwe (np. analiza zachowań klientów stacjonarnego sklepu połączona z informacją, kto z nich widział w ciągu ostatniego tygodnia billboard promocyjny marki). Jednak zderzenie pochodzących z popkultury nadmiernych („magicznych”) wyobrażeń na temat możliwości ML z zaobserwowanym status quo („iii, też mi AI, nie umie nawet kawy zrobić”) często zniechęca do wykorzystania przewag, które technologia już potrafi dostarczyć. Mimo że ML to nie SkyNet, wciąż może dać odpowiedzi na wiele pytań, które marketerzy zadają sobie każdego dnia. Podzielmy pytania na trzy obszary:
- SEO
Jak zbadać ruch i estymować efekty?
Jak zautomatyzować pracochłonne działania optymalizacyjne?
Co sprawia, że strona ma wysokie pozycje? - Content Marketing
Czy tekst jest poprawny i właściwie skonstruowany? Jaki jest jego wydźwięk?
Czy nie jest duplikatem? (wyzwanie szczególnie na portalach zawierających setki, tysiące artykułów)
O czym pisać, na jaki temat? - Growth Marketing
Jak zbudować reklamę? Jakich użyć słów, jakich grafik?
Jak zaangażować użytkownika? Np. Jakie polecenia mu serwować, aby pozostał z nami na dłużej?
Jak poprawić konwersję?
Jak podzielić budżety reklamowe?
Obecnie w większości tych kwestii działamy intuicyjnie – potrzebna jest wiedza ekspercka i wieloletnie doświadczenie. Machine Learning może pomóc uzyskać wiarygodne informacje, dzięki którym będziemy mogli zautomatyzować te działania. W jaki sposób?
SEO: jak zautomatyzować działania i zoptymalizować serwis?
I. Analiza ruchu
Specjalista SEO często mierzy się z wyzwaniem analizy nieprawdopodobnej liczby danych. W praktyce często jest ich zbyt wiele, aby móc to robić efektywnie. Bez większych trudności możemy oceniać dzięki ML następujące kwestie:
- Czy coś się wydarzyło, czy wahania są normalne?
- Czy ruch jest prawdziwy, czy generowany przez boty?
- Estymacje, co się będzie działo w najbliższym czasie.
- Wzorce użytkowników/obszary do poprawy.
Wszystkie działania, które polegają na copy paste, można i powinno się automatyzować. Ile czasu spędza się czasami na samym tworzeniu raportów? Zautomatyzować możemy:
- zaciąganie danych przez API,
- łączenie danych z różnych źródeł,
- generowanie automatycznych raportów,
- „scrapowanie” GA,
- analiza kanibalizacji słów kluczowych przez GSC,
- analiza luk optymalizacyjnych/contentowych.
To są jedynie przykładowe działania, które można zoptymalizować. Warto w codziennej pracy zastanawiać się, co mogłaby za nas zrobić maszyna.
II. „Sprzątanie serwisu”
Na podstawie tego, co wiemy już o grupowaniu danych (clustering) czy też przypisywaniu ich do określonych kategorii (kategoryzacja na podstawie znanych wyników), możemy, wykorzystując oparte na NLP liczbowe reprezentacje słów i zdań, powiedzieć, które dwa artykuły leżą „blisko siebie”. Dlatego, zamiast pracowicie analizować setki tysięcy artykułów, możemy automatycznie rozwiązać takie problemy, jak:
- kategoryzacja,
- duplikaty (i bliskie duplikaty),
- linkowanie wewnętrzne.
III. Zgadnij, czy będziesz w TOP z tym tekstem
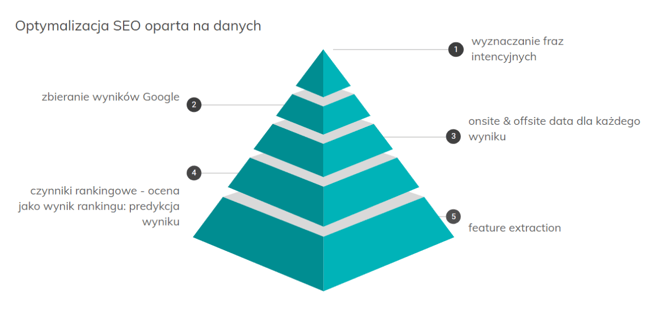
Na podstawie dostępnych danych staramy się znaleźć czynniki, które rzeczywiście decydują o tym, jakie strony lądują na najwyższych pozycjach Google. W tym celu wyznaczamy grupę bliskich fraz, zbieramy wyniki z pierwszych pozycji listy, analizujemy czynniki rankingowe i próbujemy przewidzieć, czy dany serwis ma szansę wpaść do TOP. To trudne do zrealizowania w 100%, ale przy pewnych warunkach, jeśli frazy są odpowiednio sobie bliskie, możemy uzyskać całkiem niezłe wyniki. W Whites pracujemy nad tym obszarem i doskonalimy narzędzia pozwalające na jak najtrafniejszą ocenę tekstów.
CONTENT: jak usprawnić i ocenić działania redakcyjne?
Machine Learning można wykorzystać przy następujących zagadnieniach:
- szukanie luk contentowych (o czym pisać?),
- ocena poprawności formalnej tekstu,
- badanie duplikacji/bliskiej duplikacji,
- weryfikacja tematyczności,
- analiza sentymentu,
- dobór zdjęć.
Bardziej złożonym zagadnieniem jest weryfikacja redakcyjna. Wykorzystując różne modele, możemy ją badać na kilku poziomach:
- konstrukcja formalna,
- poprawność redakcyjna,
- zgodność tematyczna (ten obszar wymaga analiz semantycznych – algorytm musi „rozumieć” tekst, a raczej: odpowiednio lokować go w przestrzeni, czyli przypisać mu adekwatne współrzędne),
- walory literackie (wymaga analiz behawioralnych – najbardziej złożone zagadnienie, aby je wykonać, algorytm musi mieć informację o tym, jak ludzie oceniają dany tekst: czy uważają go za wartościowy literacko, czy też nie. To zagadnienie nie jest szczególnie trudne obliczeniowo czy zawiłe matematycznie. Problem leży tu przede wszystkim w pozyskaniu danych uczących, czyli wielu ocen dla wielu tekstów).
Growth: Jak optymalizować konwersję?
Machine Learning jest przydatny w następujących obszarach:
- optymalizacja reklam,
- optymalizacja ustawień (automatyzacja przez API),
- optymalizacja strony pod konwersję,
- analizy użytkowników, klastrowanie grup docelowych,
- systemy rekomendacyjne,
- wykrywanie fraudów,
- planowanie budżetów.
Marki już teraz stosują wiele narzędzi opartych o uczenie maszynowe. Wystarczy spojrzeć na:
- optymalizację reklam (Google, Facebook),
- systemy rekomendacyjne (różne generatory),
- systemy analizy zachowań,
- marketing automation.
Jednak nie wykorzystują pełni potencjału, wciąż są luki, które możemy zapełnić własnymi narzędziami. Np.:
- automatyczna analiza jakości menedżera kampanii,
- analiza nadużycia reklam/afiliacji.
Bardziej skomplikowanym tematem – ale jednocześnie niezwykle rozwojowym – jest atrybucja konwersji i optymalny podział budżetów.
Planując budżet, opieramy się o własne przemyślenia, opracowujemy ścieżki konwersji, jednak nie mamy rzeczywistego potwierdzenia w danych, które obszary rzeczywiście przynoszą największe zyski. Może któryś kanał: SEO, Content Marketing, Social Media ma mniejszy wpływ na wynik, niż nam się wydaje? Być może dzięki delikatnemu przemodelowaniu, zmianie nakładów na dany obszar osiągnęlibyśmy lepsze wyniki? Może też być odwrotnie, może przepłacamy za jakiś kanał?
W atrybucji konwersji i optymalnym podziale budżetów czeka nas sporo wyzwań:
- Facebook czy Google oferują zamknięte ekosystemy, które nie analizują się wzajemnie,
- brak w analityce danych o offline,
- brak w analityce danych kosztowych o kanałach niepłatnych (SEO, social, direct),
- potrzeba danych przekrojowych z różnych branż do uzupełniania lejka.
Jak zatem można podejść do tego tematu? Zastanówmy się nad wydatkami w kontekście najlepszego zwrotu w określonym czasie.
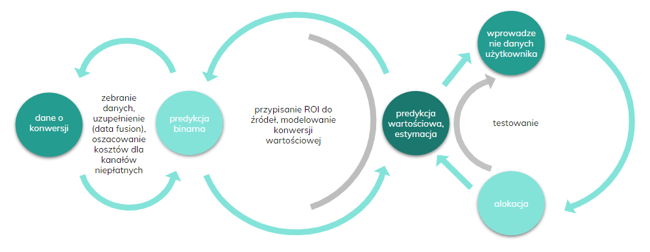
Dzięki takiemu podejściu na podstawie danych będziemy mogli określić, jaki budżet marketingowy należy przypisać do poszczególnych kanałów.
Podsumowanie
Machine Learning może wesprzeć marketingowców we wszystkich tych obszarach, w których operuje się na zbyt dużych zbiorach, aby człowiek mógł je efektywnie analizować. Tam, gdzie wykonuje się powtarzalne czynności, które nie wymagają kreatywnego myślenia, również warto pomyśleć o automatyzacji. To może sprawić, że pracownicy w większym stopniu będą się mogli się zajmować tymi zadaniami, które wymagają kreatywnego, strategicznego czy głęboko analitycznego myślenia.
Przede wszystkim: nie lekceważmy przewag, które możemy uzyskać już dziś: oszczędności czasu, mniejszej frustracji ludzi, którym odpadną nużące i mało ambitne zadania. Modele machine learningowe nie są doskonałe – to nie magia, to po prostu bardzo, bardzo dużo obliczania przybliżeń, to szukanie wzorców, które „w miarę” dopasują się do złożonej rzeczywistości. Jednak na co dzień takie dopasowanie w zupełności wystarcza do podjęcia sensownej decyzji marketingowej faktycznie „opartej na danych”.

{{ $t('pages.related_articles') }}
AI na ścieżce zakupowej. Co mówi 11. edycja Raportu Omni-commerce?
 Jak wybrać agencję digital marketingową? Whites w raporcie MMP Najlepszych Agencji 2026
Jak wybrać agencję digital marketingową? Whites w raporcie MMP Najlepszych Agencji 2026
 TikTok Shop - jak wybrać twórców i program afiliacyjny
TikTok Shop - jak wybrać twórców i program afiliacyjny